
RAG and knowledge management
Answer with evidence from your documents, measure quality/latency/cost and avoid vector store lock-in with migration and rollback.
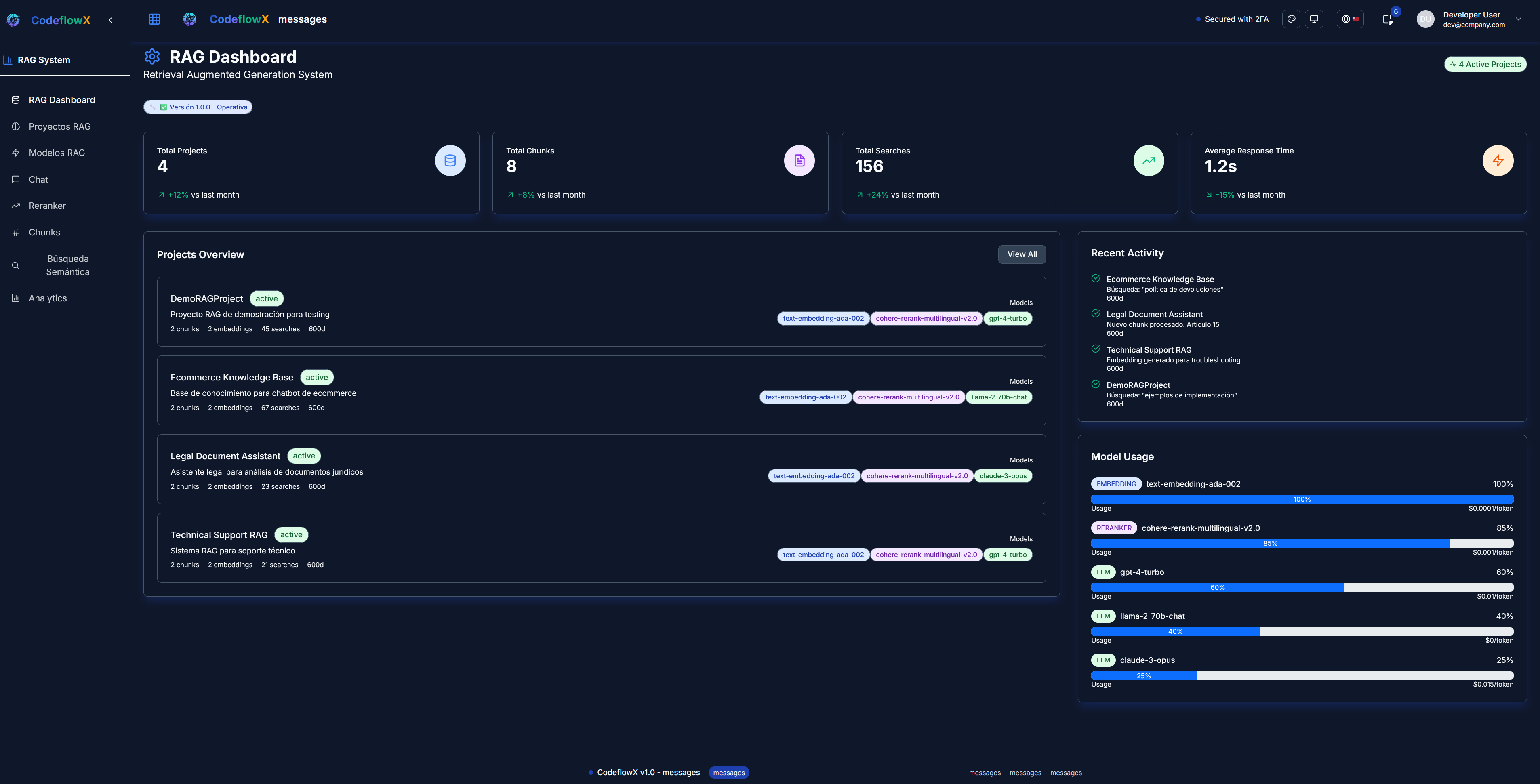
Why it's different
Evidence first: source citations and traceability for every response
No lock-in: Vector Store Manager with bidirectional migration and rollback
Operational and quality metrics ready from day one
What it includes
Ingestion and preparation
Multiple sources: files (PDF, TXT/MD, HTML), APIs (REST/GraphQL), databases (SQL/NoSQL) and webcrawler
Cleaning, chunking and automatic metadata
Validations, incremental re-ingestion and real-time synchronization
Embeddings and search
Local and commercial embeddings (adapters)
Dense + BM25 search (hybrid)
Optional reranking to improve precision
Vector Store Manager
Configuration per project/tenant
Providers: Qdrant (local) + commercial (Pinecone/Weaviate, etc.)
Migration with metadata preservation, batches and progress bar
Safe rollback and integrity verification
Evidence-based response
Retrieval + generation with source citations
Basic groundedness/factual controls
Export of responses and evidence (CSV/JSON/PDF)
Metrics you'll see
Quality: recall@k, MRR/nDCG, % responses with source, groundedness (basic)
Operation: P50/P95 latency, throughput, cost per query
Migration: total time, vectors/minute, errors and post-migration verification
How to use (typical flow)
Connect your source (files, APIs, databases or webcrawler) and define ingestion rules
Select embeddings and search type (dense/hybrid) with reranker if applicable
Configure the vector store (local or commercial)
Launch questions and validate responses with source citations
(Optional) Migrate to another provider and verify integrity; use rollback if necessary
Check our roadmap to check the availability of these components and/or functionalities
Ready to implement evidence-based RAG?
Start answering questions with source citations and avoid vector store lock-in.